深入解析 MySQL Binlog转储线程(Dump Thread)的核心操作与数据处理支持服务
在MySQL数据库的高可用与数据复制架构中,Binlog(二进制日志)扮演着至关重要的角色。而负责将主库的Binlog事件发送给从库的关键组件,正是Binlog转储线程(Binlog Dump Thread)。本文将从其核心操作、工作机制出发,并延伸至其在数据处理与存储支持服务中的应用场景。
一、Binlog转储线程的核心操作
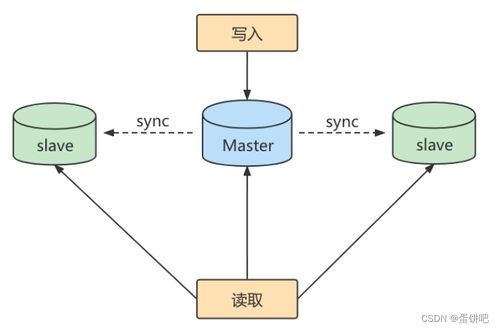
Binlog转储线程是MySQL主库(Master)上的一个后台线程,每个连接到主库请求Binlog的从库(Slave)I/O线程都会在主库上创建一个对应的Binlog Dump Thread。其主要执行以下核心操作:
- 连接管理与请求响应:当从库的I/O线程连接到主库并请求Binlog数据时,主库会为其专门创建(或复用)一个Binlog Dump线程。该线程负责维护与这个特定从库的连接会话。
- Binlog事件读取与筛选:线程根据从库发送的请求信息(如指定的Binlog文件名和位置点),定位并读取主库本地的Binlog文件。它会持续监控Binlog的变化,读取新产生的日志事件。
- 事件序列化与网络传输:将读取到的Binlog事件(格式为二进制的
Binlog_event对象)进行序列化,并通过网络连接发送给从库的I/O线程。这是一个持续推送的过程,只要连接正常且主库有新的Binlog事件产生,线程就会不断地读取和发送。
- 位置点同步与状态维护:线程会跟踪已经成功发送给从库的Binlog位置,并在从库确认接收后,主库可以据此进行一些状态维护。它确保了即使在网络中断后恢复,也能从正确的断点继续发送数据,保证了数据同步的连续性。
二、工作机制简述
其工作流程可以概括为:从库连接 → 主库创建Dump线程 → 从库发送请求(文件名+位置)→ Dump线程定位并读取Binlog → 持续发送事件流 → 从库接收并写入Relay Log → 循环直至连接断开。
三、在数据处理与存储支持服务中的关键作用
在CSDN博客等平台讨论的现代数据处理与存储支持服务(如数据仓库、实时分析、异地容灾、缓存更新等)中,基于Binlog和其转储线程的机制构成了数据流动的基石。
- 数据复制与高可用:这是最经典的应用。通过主从复制,Binlog Dump线程将主库的数据变更实时地同步到多个从库,实现读写分离、负载均衡和故障快速切换,为在线服务提供高可用性支持。
- 实时数据流处理:在大数据生态中,可以利用Canal、Debezium等工具,模拟一个MySQL从库,向主库请求Binlog。主库上的Binlog Dump线程会将数据变更事件推送给这些工具。工具解析后,可将变更事件实时发布到Kafka等消息队列,进而供Flink、Spark Streaming等流计算引擎消费,实现实时数仓构建、用户行为分析、实时推荐等。
- 异构数据同步:通过订阅Binlog事件流,可以将MySQL中的数据变更实时同步到其他类型的存储系统中,例如:
- 同步到Elasticsearch,构建强大的全文搜索功能。
- 同步到Redis,更新缓存,保证缓存数据的一致性。
- 同步到HBase或对象存储,用于历史数据归档或分析。
- 同步到另一个异构数据库(如TiDB、ClickHouse),实现数据融合与分析。
- 数据审计与回滚:Binlog完整记录了所有数据变更历史。通过解析和存储Binlog流,可以用于事后数据审计、安全分析,或者在数据误操作时,基于Binlog进行精准的数据恢复或回滚。
四、
Binlog转储线程虽然只是MySQL内部一个相对“低调”的线程,但它是整个数据库生态数据流动的“发动机”。它将数据库内部的数据变更事件,高效、有序、持续地输送给外部世界。从传统的主从复制,到现代的实时数据管道、流式数据处理和多元存储同步,其背后都依赖于Binlog Dump线程稳定可靠的工作。理解其操作原理,是设计和运维高性能、高可用的数据处理与存储服务体系的关键基础。
因此,在构建数据密集型应用的支持服务时,合理利用基于Binlog的同步机制,能够极大地提升系统的实时性、可靠性和可扩展性。
如若转载,请注明出处:http://www.520hbwl.com/product/55.html
更新时间:2026-02-25 15:30:31