从零到一建设数据中台 数据处理与存储支持关键技术汇总
在数字化转型的浪潮中,数据中台已成为企业实现数据驱动、释放数据价值的核心引擎。其核心在于将分散、异构的数据资产进行统一整合、治理与加工,形成可复用、可共享的数据服务能力,从而高效赋能前端业务。从零到一建设数据中台,数据处理与存储支持服务是至关重要的技术基石。本文将系统梳理和汇总其中的关键技术环节。
一、核心数据处理技术
- 数据集成与同步
- 批处理与实时流处理:建设初期需兼顾存量数据的批量迁移与增量数据的实时接入。常用工具有Apache Sqoop、DataX(批处理),以及Apache Kafka、Flink、Spark Streaming(实时流处理)。它们确保了数据从源头系统到中台的稳定、高效流动。
- CDC(变更数据捕获):对于数据库源,CDC技术(如Debezium、Canal)能够低延迟地捕获数据的新增、更新和删除操作,是实现实时数据同步、保证数据一致性的关键技术。
- 数据开发与计算
- 离线计算:基于Hadoop MapReduce、Apache Spark、Hive等构建大规模数据仓库,进行复杂的ETL(抽取、转换、加载)作业、数据清洗、指标加工和报表生成。
- 实时计算:采用Apache Flink、Spark Streaming等流计算框架,对实时数据流进行即时处理与分析,满足实时监控、实时推荐等业务场景。
- 交互式查询:利用Presto、ClickHouse、Apache Kylin等引擎,支持对海量数据的亚秒级到秒级的多维分析查询,提升数据探索与分析的效率。
- 数据治理与质量
- 元数据管理:建立统一的数据地图,自动采集技术元数据(如表结构、血缘关系)和业务元数据(如指标口径、业务术语),实现数据的可发现、可理解与可追溯。工具如Apache Atlas、DataHub。
- 数据质量:通过定义并监控数据的完整性、准确性、一致性、及时性等规则,构建数据质量闭环。工具如Griffin、Apache Griffin或自研平台。
- 数据标准与建模:制定企业级的数据标准与规范,并采用维度建模(如Kimball模型)或数据仓库模型,构建清晰、稳定的数据公共层(如贴源层、公共维度层、汇总层),这是数据资产可复用的核心。
二、核心数据存储技术
- 统一存储层
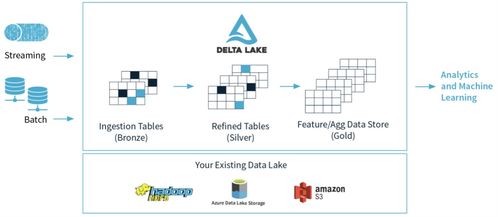
- 数据湖:以Apache HDFS、AWS S3、阿里云OSS等对象存储为核心,构建企业级数据湖,用于原始、全量数据的低成本、高可靠存储。它接纳各种格式(结构化、半结构化、非结构化)的数据,为上层计算提供统一的“水源”。
- 数据仓库:在数据湖之上,基于Hive、Iceberg、Hudi或云上数仓产品(如MaxCompute、Snowflake),构建结构清晰、模型规范的数据仓库,服务于系统性的分析与决策。
- 多样化存储引擎
- OLAP分析型存储:针对不同的查询模式,选择合适的列式存储引擎,如ClickHouse(极致查询性能)、Apache Doris(兼顾实时与离线)、StarRocks等,以支持高速多维分析。
- NoSQL与宽表存储:对于高并发点查、灵活Schema或时序数据场景,需引入HBase、Cassandra、MongoDB、时序数据库(如InfluxDB、TDengine)等作为补充。
- 图数据库:对于关系挖掘、社交网络、风控等场景,Neo4j、Nebula Graph等图数据库能高效处理复杂的关联查询。
三、支持服务与平台化
- 任务调度与运维
- 采用如Apache DolphinScheduler、Airflow等调度系统,对复杂的ETL任务流进行可视化编排、依赖管理与监控告警,保障数据处理作业的稳定运行。
- 数据服务与API化
- 建设统一的数据服务网关,将加工好的数据(如维度表、指标、用户画像标签)封装成标准、安全的API(Restful、GraphQL),供业务系统低门槛、高性能地调用,这是数据中台价值输出的最后一公里。
- 安全与权限
- 实施贯穿数据全生命周期的安全策略,包括存储加密、传输加密、细粒度的数据访问控制(基于RBAC或ABAC模型)、数据脱敏与审计日志,确保数据安全合规使用。
###
从零到一建设数据中台,数据处理与存储支持服务是贯穿始终的技术主线。企业需要根据自身的数据规模、业务场景、技术栈和团队能力,合理选择和组合上述关键技术,并注重其平台化、服务化与自动化。关键在于以终为始,围绕“数据资产化、服务化”的核心目标,构建一个灵活、高效、可信的数据基础设施,从而稳步支撑起企业数据能力的持续演进与业务创新的加速实现。
如若转载,请注明出处:http://www.520hbwl.com/product/64.html
更新时间:2026-02-25 11:35:02