大数据架构的演进 数据处理与存储支持服务的迭代路径
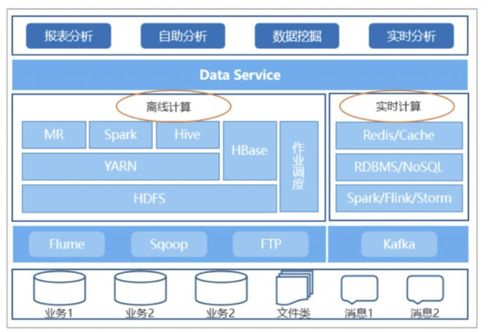
随着数据量的爆发式增长和应用场景的不断扩展,大数据架构经历了从传统批处理到实时流处理、从单一存储到多模态服务的重要迭代。这一演进不仅提升了数据处理效率,也推动了存储支持服务的多样化和智能化发展。
在早期阶段,大数据架构主要依赖Hadoop生态系统,以批处理为核心。MapReduce作为典型的数据处理引擎,适用于离线数据分析任务;而HDFS(Hadoop分布式文件系统)提供了可靠的存储基础。批处理模式延迟较高,难以满足实时业务需求。
随着技术的发展,架构开始向Lambda和Kappa等混合模式迭代。Lambda架构结合了批处理和流处理层,通过批层处理历史数据、流层处理实时数据,再通过服务层合并结果。这引入了如Apache Spark(用于批处理)和Apache Flink(用于流处理)等引擎,显著提升了处理灵活性。同时,存储支持服务也从单一的HDFS扩展至NoSQL数据库(如HBase、Cassandra)和对象存储(如AWS S3),以支持多样化的数据模型和访问模式。
近年来,云原生和实时化成为迭代的关键方向。架构演进为以Kubernetes为基础的容器化部署,数据处理服务如Apache Kafka和Apache Pulsar提供了高吞吐的消息队列,支持事件驱动数据流。存储服务则进一步融合了数据湖和数据仓库概念,例如Delta Lake和Snowflake,实现了ACID事务和统一查询,提高了数据一致性和可管理性。AI驱动的自动化运维和Serverless计算模型,正在降低大数据架构的复杂性,让数据处理和存储服务更弹性、更智能。
总体而言,大数据架构的迭代体现了从集中式到分布式、从离线到实时、从单一存储到多服务集成的转变。未来,随着边缘计算和物联网的普及,架构将进一步向去中心化和智能化演进,数据处理和存储支持服务将更注重低延迟、高可用和可持续性,赋能企业在数据洪流中持续创新。
如若转载,请注明出处:http://www.520hbwl.com/product/25.html
更新时间:2025-11-29 23:55:04